-
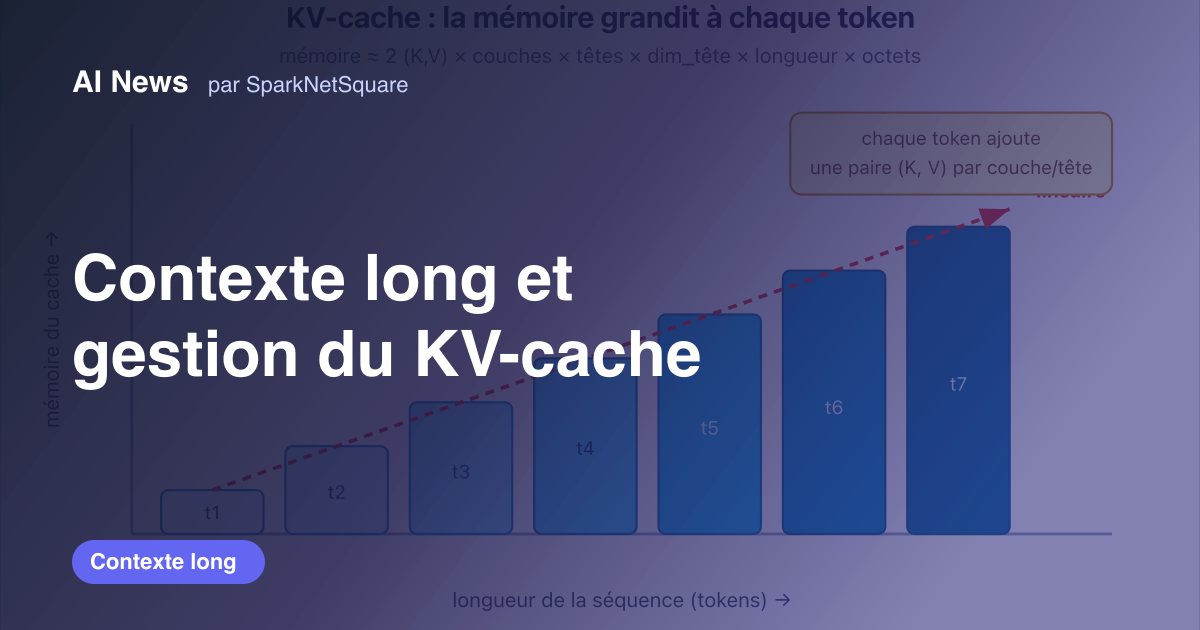
Contexte long et gestion du KV-cache
Pourquoi le contexte long est coûteux : attention O(n²) et KV-cache linéaire. MQA/GQA, FlashAttention, PagedAttention, RoPE/YaRN, attention sinks.
12 min de lecture -
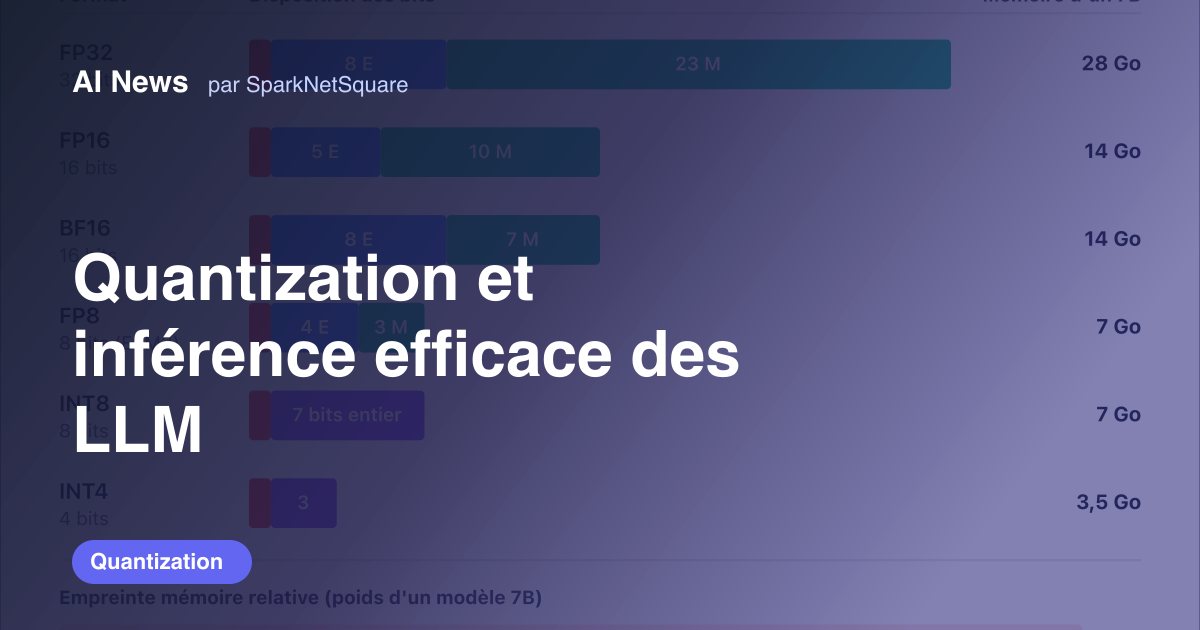
Quantization et inférence efficace des LLM
Formats FP32/FP16/BF16/FP8/INT8/INT4, GPTQ, AWQ, SmoothQuant, GGUF, NF4, outliers, batching continu, PagedAttention et décodage spéculatif.
13 min de lecture
AI AI News Se connecter
Rédiger ![]() Connecté via GitHub Connecté via Google Connecté via X Connecté via Apple e-mail
Connecté via GitHub Connecté via Google Connecté via X Connecté via Apple e-mail