Inférence
Sign in to follow this category-
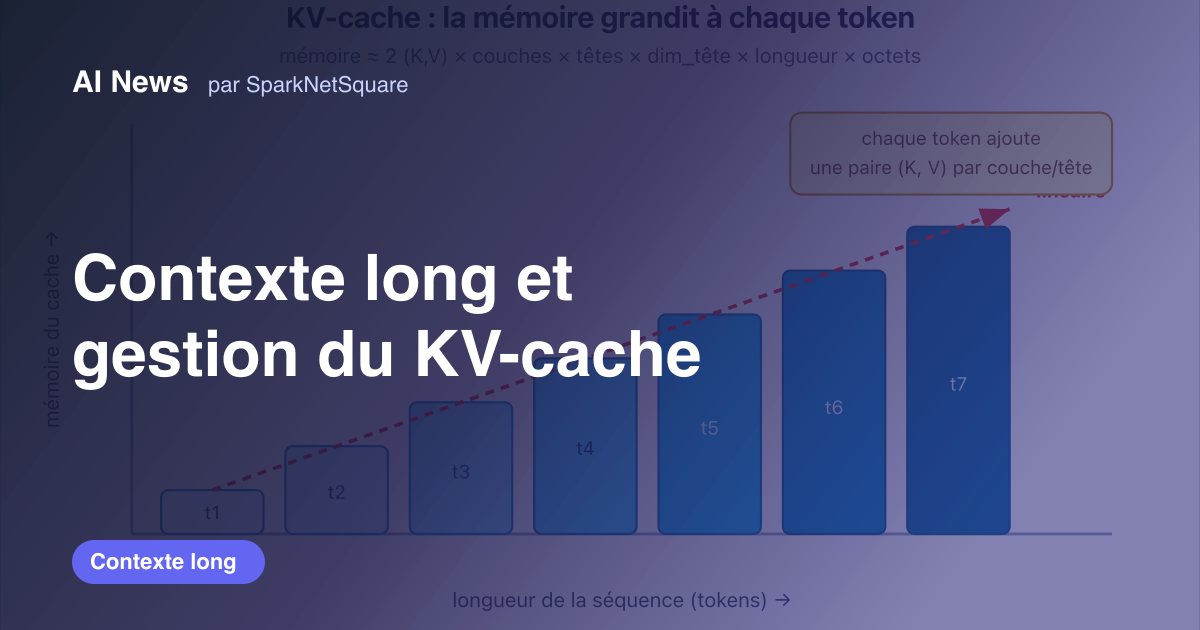
Long context and KV-cache management
Why long context is costly: O(n²) attention and a linear KV cache. MQA/GQA, FlashAttention, PagedAttention, RoPE/YaRN, attention sinks.
12 min read -
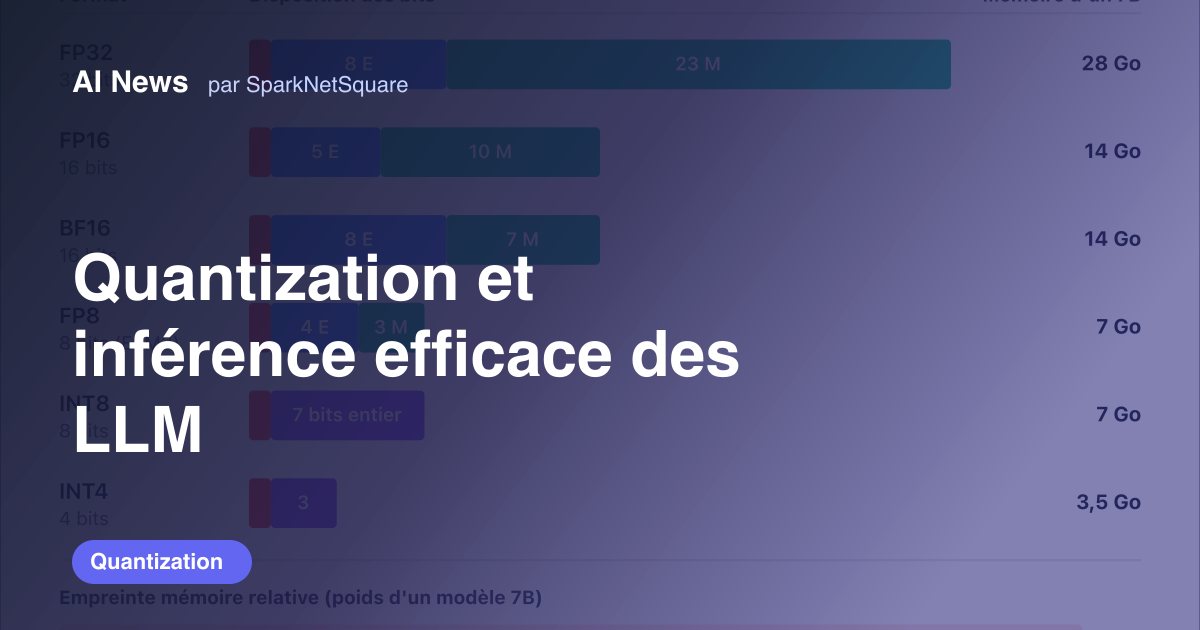
Quantization and efficient LLM inference
FP32/FP16/BF16/FP8/INT8/INT4 formats, GPTQ, AWQ, SmoothQuant, GGUF, NF4, outliers, continuous batching, PagedAttention and speculative decoding.
12 min read